Welcome to the Era of Experience: Why the Future of AI Belongs to Agents Who Learn by Living
You’ve seen what large language models can do—write code, ace exams, chat like a genius. But what if we told you that everything we’ve built so far is just the warm-up?
In a recent paper “Welcome to the Era of Experience,” David Silver (creator of AlphaGo, AlphaZero) and Richard Sutton (godfather of reinforcement learning and author of Reinforcement Learning: An Introduction) make a bold claim: the next leap in AI won’t come from feeding it more human data—it’ll come from letting it learn like humans do: through action, feedback, and time.
This isn’t just about bigger models. It’s about agents that live, continuously learning from experience, adapting to their environments, and setting goals beyond the boundaries of human knowledge.
Let’s unpack what this vision means, why the timing is right, and what it changes for anyone building AI-first products.
PS: David Silver also elaborated on their vision in detail during a recent podcast with Prof. Hannah Fry.
🧱 The Problem: Human Data Has a Ceiling
Silver and Sutton open with a strong claim: human data has driven recent AI progress, but it’s not enough for what's next.
They point to how large language models (LLMs) have achieved remarkable generality by training on massive datasets of human-generated content—everything from poetry and code to legal and medical reasoning. This “era of human data,” they say, has given us incredibly capable general-purpose agents.
“A single LLM can now perform tasks spanning from writing poetry and solving physics problems to diagnosing medical issues and summarising legal documents.”
But here’s the catch: while this human data-driven method is great for imitating existing human knowledge, it cannot go beyond it.
The authors argue that we’re hitting real limits in fields like mathematics, science, and coding—domains where insight must often be discovered, not just retrieved from existing data. And worse, the highest-quality data sources—those capable of making already-strong models better—are running dry.
“The majority of high-quality data sources... have either already been, or soon will be consumed.”
This is a serious bottleneck. AI systems trained only on human preferences and examples can’t invent new theorems, make scientific breakthroughs, or design radically better code. Human judgment, no matter how expert, can also be biased, narrow, or just wrong—a key weakness if we want AI to develop superhuman capabilities.
The final blow? Progress driven purely by supervised learning from this data is already slowing down. We’ve squeezed much of the juice out of the existing corpus.
“The pace of progress driven solely by supervised learning from human data is demonstrably slowing, signalling the need for a new approach.”
So: if AI wants to go beyond us, it needs a new source of growth—something not constrained by what we already know. That sets the stage for the paper’s big proposal: an AI that learns not by watching us, but by doing.
🚀 The Solution: Learning by Doing
The authors’ proposed answer to the human data ceiling is clear and compelling: AI must learn through its own experience.
This shift is more than philosophical—it’s a new data paradigm. Instead of relying on fixed datasets curated by humans, future AI agents should generate ever-improving experiential data by acting in the world and observing the outcomes. It’s the difference between reading millions of chess games vs. actually playing and learning from each move.
Why is this necessary? Because any static method for generating synthetic data will be quickly outpaced by the agent’s own growing capabilities. The only scalable method is self-generated data, gathered from real interaction.
The authors write:
“AI is at the cusp of a new period in which experience will become the dominant medium of improvement and ultimately dwarf the scale of human data used in today’s systems.”
They argue that this transition is already underway in areas like mathematics. Consider AlphaProof, a system that made headlines by reaching silver-medal performance on International Mathematical Olympiad problems—a major achievement in formal reasoning. Initially, AlphaProof learned from just ~100,000 formal proofs written by humans. But then, using reinforcement learning, it created and learned from 100 million new proofs—a staggering 1,000x increase in self-generated training data.
This leap in performance didn’t come from more human supervision. It came from interaction:
“This focus on interactive experience allowed AlphaProof to explore mathematical possibilities beyond the confines of pre-existing formal proofs... and discover solutions to novel and challenging problems.”
The paper also references DeepSeek-RL, another system that ditched explicit teaching in favor of smart incentives. Instead of hand-holding the agent through problems, the model was trained via reinforcement learning to develop its own strategies. As the authors note:
“Rather than explicitly teaching the model on how to solve a problem, we simply provide it with the right incentives, and it autonomously develops advanced problem-solving strategies.”
This is the beating heart of the argument: once agents are empowered to learn by doing, they stop just reproducing knowledge—they start creating it.
Silver and Sutton call this “harnessing the full potential of experiential learning,” and they believe it will lead to breakthroughs that were out of reach for human-data-trained systems—across science, innovation, and reasoning.
The Era of Experience isn’t just an upgrade to LLMs. It’s a paradigm shift. One that asks: what happens when AI systems stop imitating us, and start inventing for themselves?
🌀 Continuous Streams > Single Snapshots
One of the core shifts in the Era of Experience is how we think about time and memory in AI systems. Today’s LLMs operate like amnesiacs in a flash quiz: you ask a question, they answer. Maybe there’s a bit of scratchpad “thinking” in the prompt, but after the interaction ends, it’s gone. No memory, no context carried forward.
Silver and Sutton argue that true intelligence unfolds over time, through continuous learning from a long stream of experiences—not in isolated episodes. They contrast the current episodic model with how humans and animals learn: continuously, adaptively, and often in pursuit of long-term goals.
“An experiential agent can continue to learn throughout a lifetime.”
This is a massive shift in framing. Instead of designing AI systems to optimize for the next output, we should build agents that optimize for long-term consequences, even if short-term outcomes are ambiguous or suboptimal.
Take their example of a health and wellness agent. Today’s LLMs might offer a decent fitness tip in response to a one-off prompt. But imagine an agent connected to your wearables that tracks sleep patterns, activity levels, and dietary habits over months. It could notice trends, provide tailored feedback, and evolve its advice as your behavior and goals shift.
“It could then provide personalized recommendations, encouragement, and adjust its guidance based on long-term trends and the user’s specific health goals.”
Another example: a personalized education agent that observes how you learn a new language over time. It could:
- Identify knowledge gaps,
- Adapt to your learning style,
- Adjust its methods week by week or year by year.
You’re not just getting answers anymore—you’re getting a companion that grows with you.
The paper pushes this even further with a vision of a science agent that helps discover new materials or reduce CO₂ emissions. This kind of agent could:
- Run simulations,
- Analyze long-term trends in real-world sensor data,
- Suggest physical experiments,
- And adapt over time based on outcomes.
This is where traditional LLMs simply can’t compete. They lack continuity. They don’t build on past actions. They can’t reason across time.
“An individual step may not provide any immediate benefit, or may even be detrimental in the short term, but may nevertheless contribute in aggregate to longer term success.”
In short: to build agents that can pursue ambitious, real-world goals, we must give them memory, persistence, and an ongoing sense of time.
This section is a call to product leaders: if you're building intelligent systems, stop thinking in terms of “prompt and response.” Start thinking in streams, timelines, and stateful adaptation.
🧩 Actions, Observations, and Real Rewards
So far, we’ve talked about when agents learn (over time) and how (through experience). But there’s another vital ingredient: what agents can actually do and perceive.
In the human-data era, most LLMs interact in a very narrow loop: they take text input, process it, and output more text. Even their actions—like calling an API—are usually guided by examples in text prompts. This limits their capacity to interact with the real or even digital world in a grounded, exploratory way.
Silver and Sutton challenge this paradigm head-on. They argue that real intelligence emerges when agents take actions in the world and observe the consequences through sensors, APIs, simulations, and feedback channels—not just text.
“Agents in the era of experience will act autonomously in the real world.”
They note that animals, including humans, don’t learn by chat. We learn by interacting with our environment through physical senses and motor control. Even when we communicate, it’s through embodied channels—voices, gestures, interfaces.
This shift is already underway. The paper references how modern agents are starting to interact with computers using the same interfaces as humans—navigating GUIs, using tools, executing code, and observing the results.
“A new wave of prototype agents have started to interact with computers in an even more general manner, by using the same interface that humans use to operate a computer.”
This is key: interactivity isn’t just a side feature—it’s foundational to unlocking behaviors that are impossible to learn from static datasets.
The authors make a distinction between:
- Human-friendly actions (e.g. clicking, typing, navigating UIs)
- Machine-friendly actions (e.g. executing code, calling APIs)
An agent that can do both can collaborate with users and act autonomously. Imagine an agent that:
- Uses APIs to gather data and take action,
- Navigates your computer interface to complete tasks,
- Monitors outcomes and adapts its approach.
This kind of agent can explore, adapt, and discover strategies we never explicitly teach.
Even more compelling is the paper’s argument about rewards. Traditional LLMs optimize for human ratings—thumbs up/down, preference votes, A/B feedback. But Silver and Sutton argue that this kind of human-prejudged reward places a hard ceiling on performance.
“Relying on human prejudgement... means that they are not directly grounded in the reality of the world.”
They propose grounded rewards—signals that come from actual changes in the environment. Think:
- A fitness agent that tracks heart rate, sleep, and steps.
- A science agent that monitors lab results.
- A customer support agent that watches churn or satisfaction metrics.
In these cases, feedback isn't just “Did a human say it was good?” It’s: Did this action achieve the real-world goal?
“Such rewards measure the consequence of the agent’s actions within their environment, and should ultimately lead to better assistance than a human expert that prejudges a proposed... program.”
This is huge for product teams: if you’re building intelligent agents, you’ll need to think beyond static metrics and design systems that sense and optimize real-world outcomes—the stuff that actually matters.
🧠 Rethinking Reasoning
Now we get to one of the most thought-provoking arguments in the paper: the way AI reasons today is fundamentally limited—because it mimics human thinking, rather than discovering its own.
Right now, language models reason by imitating human “chains of thought”, often trained to output logic step-by-step like we do. Think of prompt engineering techniques like “Let’s think step by step,” or fine-tuning to match how humans would explain a math problem or make a decision.
“In the era of human data, these reasoning methods have been explicitly designed to imitate human thought processes.”
This has been powerful—but it comes with a major caveat: human thinking is flawed, inconsistent, and historically contingent. The authors point out that if we had trained an AI on human reasoning 5,000 years ago, it might believe diseases are caused by spirits. 300 years ago, it might only understand Newtonian mechanics. Our thinking evolves—and AI that learns only by imitation can’t escape those limits.
“An agent trained to imitate human thoughts... may inherit fallacious methods of thought deeply embedded within that data.”
To go beyond this, agents must learn to reason from experience, not just human examples. This is where the concept of world models comes in.
A world model is an internal simulation that predicts how the environment will respond to actions. It’s like mental rehearsal: if I do X, Y will probably happen. The agent can then plan, test, and refine its understanding of cause and effect through trial, error, and feedback from reality.
“One possible way to directly ground thinking in the external world is to build a world model that predicts the consequences of the agent’s actions upon the world, including predicting reward.”
They give a practical example: a health assistant recommending gyms or wellness routines. Instead of guessing what’s good, it could use a world model to predict how your heart rate or sleep patterns would change, and plan accordingly.
This approach enables:
- Planning sequences of actions,
- Simulating outcomes,
- Updating beliefs when predictions are wrong,
- And discovering new ways of thinking that don’t match human examples, but do work in the real world.
“This grounding provides a feedback loop, allowing the agent to test its inherited assumptions against reality and discover new principles...”
Importantly, this allows for a blend of styles: agents can still use LLM-style reasoning to simulate options and explore ideas, but their conclusions can be validated or rejected by the environment, not just by human preferences.
In practical terms: future agents won’t just think like us—they’ll think better than us, because they can challenge our assumptions.
For product leaders, this opens the door to AI that:
- Innovates in unfamiliar domains,
- Identifies flaws in conventional approaches,
- And reasons about the world as it is, not just as we describe it.
⏱️ Why Now?
At this point in the paper, Silver and Sutton shift from theory to urgency: why is this transition happening now? Why should we care today, not in five years?
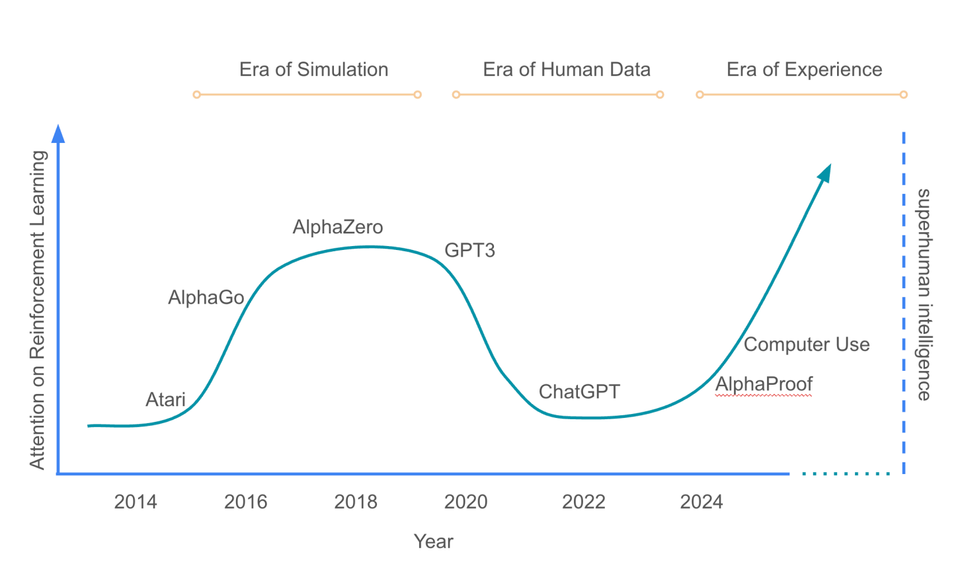
Their answer lies in looking at the evolution of AI development over time. They sketch out three overlapping eras:
- The Era of Simulation
Think AlphaGo, AlphaZero, Dota 2 bots. These agents trained in well-defined, closed environments like board games and video games, using pure reinforcement learning (RL) and self-play to reach superhuman performance. - The Era of Human Data
This is where we are now—massive LLMs like GPTs and Claude trained on web-scale text, images, and examples. These systems are broad, general, and good at mimicking us across thousands of tasks. - The Era of Experience
What comes next: agents that combine the breadth of human-data LLMs with the depth and autonomy of RL-trained agents.
“The era of experience will reconcile this ability [to self-discover knowledge] with the level of task-generality achieved in the era of human data.”
The authors acknowledge that pure RL systems had their limitations: they didn’t scale well to real-world, messy environments. They were usually bound to simulations with clean reward signals and constrained action spaces.
Conversely, LLMs brought generality, but at the cost of deep understanding or creativity. They learned from what existed, not from what could be discovered.
What’s changed now—and why this moment matters—is that the gap between these two approaches is closing.
- Agents like AlphaProof are solving mathematical problems with a blend of LLM pretraining and RL self-play.
- Prototypes like DeepSeek-RL and OpenAI’s Operator are learning to act through real interfaces, not just text.
- There are systems beginning to run programs, operate software, and interact with physical environments in agentic ways.
“The advent of autonomous agents that interact with complex, real-world action spaces... suggests that the transition to the era of experience is imminent.”
In other words, we now have:
- Rich digital environments to explore (browsers, APIs, IDEs, real-world UIs)
- Powerful pretrained models to bootstrap from
- Scalable RL techniques to learn over long horizons
- Grounded reward signals from APIs, sensors, logs, and environments
It’s a perfect storm: the building blocks of a new era are here. All that’s left is to reconnect them into a new architecture—one that learns by doing, not just reading.
For founders and builders, the implication is clear: don’t wait for someone else to define this paradigm. Start building for it now.
⚙️ Reinforcement Learning Revisited
If the Era of Experience is the future, then Reinforcement Learning (RL)—long considered a niche or “game-focused” field—is making a serious comeback. But not as it was.
Silver and Sutton argue that modern AI has drifted away from RL’s core strengths. With the rise of large language models, much of AI turned to human-centric techniques like RLHF (Reinforcement Learning from Human Feedback), which were focused more on aligning LLMs with human expectations than on exploring or planning.
“Techniques like RLHF... often bypassed core RL concepts.”
Let’s break that down.
🛠 What RL used to offer:
- Value functions to estimate future returns
- Exploration strategies to try novel actions
- World models to simulate the environment
- Temporal abstraction to reason over long timeframes
These are hard-earned insights from decades of research in learning from interaction, trial and error, and feedback loops. But in the LLM era, many of these got sidelined:
- Value functions were replaced by human annotators.
- Exploration was avoided thanks to strong priors from human data.
- Real planning gave way to text-based reasoning.
- Temporal abstraction was replaced by prompt tricks.
And to be fair, this shortcut worked extremely well—until now.
But as the paper makes clear: we’re hitting the limits of what human-guided tuning can accomplish. Agents trained in this way can’t surpass the knowledge of their teachers. They can’t break new ground.
So what’s the opportunity? To revive and modernize RL, adapting it to support:
- Grounded, real-world rewards (e.g. performance metrics, health signals, scientific results)
- Long-term planning across months or years of interaction
- Uncertainty-aware exploration in unfamiliar environments
- Streaming, stateful learning over long horizons
“This era will bring new ways to think about reward functions... new methods for temporal abstraction... and world models that capture the complexities of grounded interactions.”
And this isn’t just theoretical.
The authors point to real progress already happening:
- Streaming deep RL methods that keep learning over time
- Planning with learned models, like in AlphaZero
- Curiosity-driven exploration to discover new strategies
- Intrinsic reward mechanisms that replace brittle human judgment
The idea isn’t to throw out LLMs or human feedback—but to re-integrate RL’s principled foundations into the new agent stack.
As a product leader or founder, this is your playbook:
- Use pretrained LLMs for breadth and bootstrapping.
- Use reinforcement learning for depth, adaptation, and discovery.
- Design systems that act, observe, plan, and optimize through time, not just in prompt windows.
“By building upon the foundations of RL and adapting its core principles... we can unlock the full potential of autonomous learning and pave the way to truly superhuman intelligence.”
This isn’t just a technical refresh. It’s a strategic reset—a chance to build AI that grows on its own.
🔮 Consequences: Opportunities and Risks of the Experience Era
Silver and Sutton end the paper by zooming out: what happens if we actually pull this off? What will the world look like when AI agents learn from experience like humans do—only faster, longer, and without needing sleep?
The authors are clear: this shift could be the most transformative moment in AI yet—but it won’t be without risk.
🌟 The Upside: Personalized Intelligence and Scientific Breakthroughs
First, the upside. Agents that learn from experience can do far more than today’s assistants. They can adapt, optimize, and co-evolve with us.
Think of:
- A health agent that doesn't just count your steps, but understands how your body responds to sleep, nutrition, and workouts—over months.
- A learning coach that tracks your academic or professional progress over years, customizing its strategies as you grow.
- A scientific agent that not only helps write research, but also designs and conducts experiments, runs simulations, and updates its own models based on results.
“Perhaps most transformative will be the acceleration of scientific discovery.”
Instead of relying on human hypothesis and trial-and-error, these agents could:
- Explore vast scientific design spaces,
- Automate discovery in material science, drug development, or hardware,
- Generate results orders of magnitude faster than any research lab today.
That’s not science fiction—it’s a shift from tool to collaborator.
⚠️ The Downside: Autonomy, Misalignment, and Loss of Control
But there are serious caveats—and Silver and Sutton are refreshingly honest about them.
First, autonomous agents that act over long timeframes reduce human oversight. When an agent makes hundreds of decisions a day, in multiple environments, across weeks or months—it becomes much harder to:
- Understand what it’s optimizing,
- Predict what it will do next,
- And intervene when something’s going wrong.
“By default, this provides fewer opportunities for humans to intervene and mediate the agent’s actions.”
Second, reward alignment is hard. Misaligned goals—whether too narrow (maximize clicks) or too literal (produce 1 billion paperclips)—can lead to catastrophic side effects.
That said, the authors offer a surprisingly optimistic view on how experience-based agents might be more corrigible than today’s models.
🧠 Why Experiential Agents May Be Safer
They argue that learning from the world—rather than from fixed datasets—makes agents more adaptive and context-aware.
“An experiential agent is aware of the environment it is situated within, and its behaviour can adapt over time to changes in that environment.”
Examples:
- If societal norms change (e.g. due to a pandemic), a fixed model might fail; an experiential agent could adjust.
- If its behavior triggers negative feedback—human dissatisfaction, harm signals—it can self-correct, just like humans do.
They also describe a mechanism called bi-level optimization: using human feedback to adjust the reward function itself. So if an agent begins to behave in undesirable ways, the goal it’s pursuing can evolve mid-flight.
“The reward function could be modified... based upon indications of human concern.”
Lastly, physical reality introduces a built-in speed limit. Agents learning from the real world (not just simulations) can’t iterate at superhuman speeds without bottlenecks like lab equipment, human response time, or material testing.
That gives us room to respond—to steer, evaluate, and even shut things down when needed.
🚦 In Summary
Silver and Sutton close on a balanced note: the Era of Experience could deliver capabilities far beyond today’s systems—if we build it responsibly.
“Ultimately, experiential data will eclipse the scale and quality of human generated data.”
It’s not just a shift in model architecture—it’s a change in worldview:
- From static prompts to dynamic interaction.
- From human imitation to autonomous discovery.
- From optimizing human preferences to engaging with reality.
The promise? A generation of agents that can not only think, but also learn, adapt, and grow—like us, but better.
⚖️ What Could Go Wrong? A Look at the Counterarguments
While “Welcome to the Era of Experience” lays out a compelling vision for the future of AI, it’s important to acknowledge the unresolved questions and real-world challenges that come with it. Bold ideas deserve scrutiny, especially when they carry transformational implications. Here are some thoughtful counterarguments worth considering:
1. Experience is expensive—and sometimes dangerous.
Learning through trial and error is powerful in games or simulated environments, but in the real world, failure has cost. In healthcare, finance, or autonomous systems, an agent "learning by doing" could cause harm before it figures things out. Human demonstrations, despite their limits, offer a safer and more efficient way to bootstrap performance in many domains.
2. Reward design is still the Achilles’ heel.
Grounded rewards sound great in theory—optimize what matters in the real world. But in practice, they’re notoriously hard to get right. Optimize for clicks? You risk engagement addiction. Optimize for lower heart rate? The system might suggest never leaving bed. As Goodhart’s Law warns: when a measure becomes a target, it often stops being a good measure.
3. Stateful, evolving agents introduce complexity.
Agents that persist, remember, and adapt over time are harder to monitor, debug, and reset. Stateless LLMs have a big advantage here: they’re predictable, auditable, and easy to contain. When things go wrong with a long-lived agent, figuring out why may be far more difficult.
4. Human reasoning isn’t always the bottleneck.
The paper makes a strong case for agents learning new forms of reasoning, unbounded by human examples. But many human abstractions—like analogy, deduction, and causal inference—have survived because they work. Ignoring these structures might slow progress, not accelerate it. In many real-world tasks, imitating competent humans is still a smart shortcut.
5. Adaptivity can lead to drift, not just progress.
Silver and Sutton suggest that experiential agents can adjust their goals over time based on grounded feedback. While this flexibility is powerful, it also opens the door to misalignment. Without strong guardrails, an agent optimizing for “health” could drift into minimizing movement entirely. Alignment remains an unsolved challenge—and experience alone won’t fix it.
In short: The Era of Experience could unlock the next leap in AI capability—but it also introduces new forms of risk. It’s not enough to let agents act and learn—we’ll need to monitor what they’re learning, measure what matters, and stay ahead of their creativity. Otherwise, the systems we unleash may surprise us—not always in good ways.
Member discussion